

 | ♣_______ Page mise à jour le 1er juillet 2019 vers 06h40 TUC |
Décryptage d'une page du Livre de vie
Introduire cette section est certainement l'une des choses les plus malaisantes .
Le Livre de vie est le nom donné par un prêtre du diocèse d'Orléans à son journal personnel, qui se présente sous la forme d'un texte crypté d'environ trois cents pages. Ce caractère cryptographique sera le seul abordé ici. Pour les autres aspects, on pourra se reporter à cet article [⇒] (assez bref) paru sur le site de France Bleu ou cet autre [⇒] (plus détaillé) publié dans Le Monde .
Sommaire
La source
Un peu de vocabulaire
Le chiffrement
Table de codage
Transcription et décodage
Notes
[In]certitudes
Quelques observations sur les mesures
Livre et carnet
La source
Klaus Schmeh, qui cite ce texte parmi les cent principaux cryptogrammes non résolus (sous le numéro 95), a publié le 21 janvier 2019, dans la version en anglais de son blog, un article intitulé Can you break this encrypted diary… [⇒], accompagné de la photographie de la page 83 du Livre de vie . Environ un mois plus tard paraissait sur le même blog un second article Tony Gaffney has broken… [⇒] donnant le décryptage du texte effectué par Tony Gaffney.
Un peu de vocabulaire
Par convention, dans ce qui suit,
| LdV | désigne la page du Livre de vie analysée ici | Exemples |

| (*) y compris les chiffres et la ponctuation. Pour la distinction entre alphabets complet et réduit , voir plus bas –d. | |||
| [en]coder décoder | transformer un texte clair en crypté transformer un texte crypté en clair | selon un code que l'on connaît | NB-Ces distinctions ne correspondent pas en tous points à celles qui sont proposées dans la page consacrée au manuscrit Voynich [⇒] ; mais on n'emploie pas la même pelle pour creuser un fossé ou pour servir de la tarte…) |
| décrypter | traduire en clair un texte chiffré dont on ignore le code ( = retrouver ce code puis décoder le texte) | ||
| crypté [en]codé chiffré | sont équivalents | ||
| décodé en clair | |||
| transcription | remplacement par une lettre de chaque signe du texte chiffré, dans une relation bi-univoque | ||
| NB- tant qu'on n'a pas décrypté le texte, chaque couple signe–lettre est choisi plus ou moins arbitrairement et ne préjuge pas du code, même si, dans la pratique, on est obligé de faire des hypothèses sur la nature de ce dernier ; mais nous ne sommes pas ici dans ce cas de figure. | |||
Le chiffrement
À la base, LdV est chiffré suivant un système par substitution où chaque lettre est remplacée par un signe, toujours le même. Ce procédé a le mérite d'être facile d'emploi mais il présente l'inconvénient d'être également facile à décrypter, en comparant la fréquence des signes dans le texte chiffré avec celle des lettres dans un échantillon quelconque de textes en clair de la même langue.
Quelques principes supplémentaires rendent (donc ?) le décryptage plus complexe :
- la ponctuation se réduit à un signe unique valant tantôt une virgule, tantôt un point-virgule (le découpage du texte en paragraphes quotidiens permet de se passer du point) ; l'apostrophe et le trait d'union ont chacun leur propre signe ;
- les espaces sont supprimées ;
- peut-être pour compenser la règle précédente, il y a deux alphabets distincts : l'un pour le premier signe d'un mot (qui sera appelé ici alphabet/signe initial ), l'autre pour chacun des signes suivants (appelé ici alphabet/signe ultérieur ) ;
NB- cette particularité est de type un vers plusieurs : un l pourra être codé soit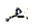 (un livre ) soit
(un livre ) soit 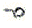 (un clou ) ; le décryptage s'en trouve compliqué mais le décodage n'est pas perturbé ;
(un clou ) ; le décryptage s'en trouve compliqué mais le décodage n'est pas perturbé ; - les signes diacritiques sont ignorés :
 encode aussi bien à ou â que a ;
encode aussi bien à ou â que a ;
NB- cette absence de diacritiques est de type plusieurs vers un : un mot codé Eleve pourra se lire soit élevé soit élève ; quand il est employé à grande échelle (par exemple en gématrie), un tel système aboutit à un texte ambigu ; dans le cas présent, l'équivoque reste limitée mais elle empêcherait d'utiliser un programme simple pour passer de la transcription (ou du texte chiffré analysé par OCR) au texte en clair ; - il y a plusieurs formes de e ultérieur :
 ,
,  ou
ou  .
.
NB1- ces formes semblent employées indifféremment, même si le point apparaît plutôt dans la première partie du mot, les autres formes, dans la seconde moitié ; voir plus bas pour leur transcription ;
NB2- il faut y ajouter les signes pointés dont il sera question en u ;
NB3- le choix du point pour le e paraît surprenant à force d'évidence, puisque c'est ainsi qu'est codé le e en morse (comme aucun radio-amateur ni aucun scout ne doit l'ignorer). - quand une lettre est redoublée (comme dans difficile à admettre ), la seconde occurrence est remplacée par
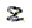 ;
; - si une lettre est suivie d'un e , le point du e peut être inclus dans le signe (par exemple ue
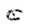 au lieu de
au lieu de 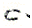 ) ;
) ;
NB1- contrairement aux règles précédentes, il s'agit d'une simple possibilité ; d'ailleurs certains signes ne permettent pas cette inclusion (par exemple D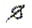 ou n
ou n 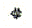 ) ;
) ;
NB2- cette particularité pose un problème délicat pour les statistiques ; que faire de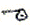 ?
?
• y voir un suivi d'un (c'est ainsi que le signe fonctionne ) ?
• y voir un signe autonome (de la même façon que e et é sont deux lettres différentes) ?
• entre les deux, y voir simplement une variante de (comme l'avait fait Richard Santa-Coloma dans un commentaire antérieur au décryptage) ?Dans le tableau statistique ci-dessous, la colonne Ⓐ représente la seconde option (qui me paraît la plus naturelle ).
Table de codage et principes de transcription
Cette table reprend celle que Tony Gaffney a publiée, en y apportant quelques modifications dont la principale est la distinction entre alphabet initial et ultérieur. →→ Dans la transcription
NB- les caractères erronés ou hypothétiques sont pris en compte dans les statistiques. Le texte décodé reprend la transcription mais
|  |
Transcription et décodage juxtalinéaires
NB2- Les appels de notes se trouvent sous la ligne de transcription/décodage correspondante.
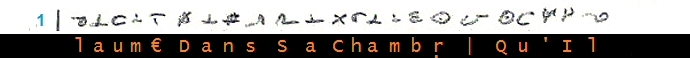
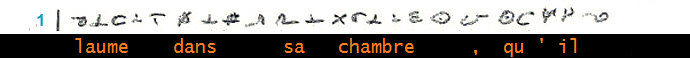 _________ (1)
_________ (1)
 ___________________________ (2)
___________________________ (2)

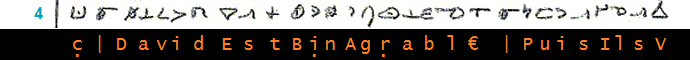
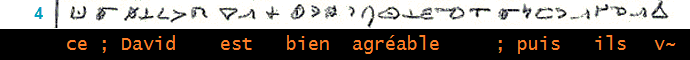

 ______________________________________________ (3)
______________________________________________ (3)
 __________________________________ (4)
__________________________________ (4)
 _______________________________________________ (5)____ (5)__ (3)
_______________________________________________ (5)____ (5)__ (3)
 _____________________________________ (6)
_____________________________________ (6)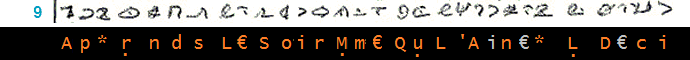
 ______________________________________________________________ (7)_______ (8)
______________________________________________________________ (7)_______ (8)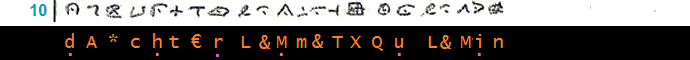
 __________________________ (9)______________ (4)
__________________________ (9)______________ (4)







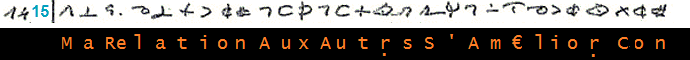

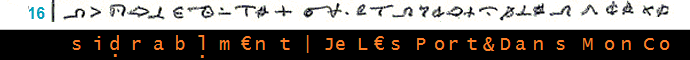
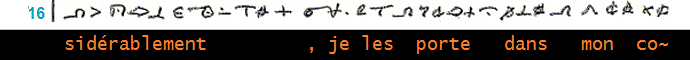
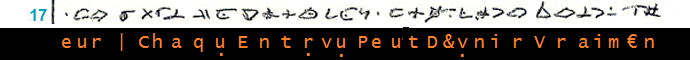
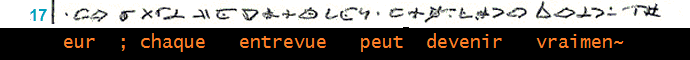


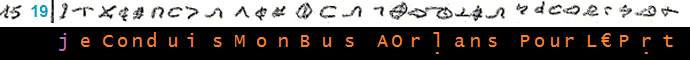


 _____________________________________________________ (10)
_____________________________________________________ (10)
 ________________________________________________________________________________ (10)
________________________________________________________________________________ (10)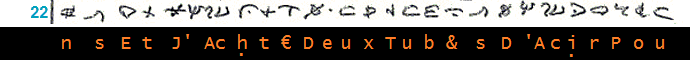

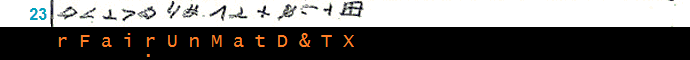
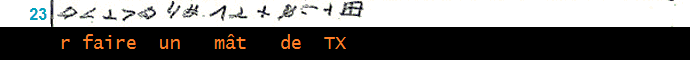 __________________________________________ (4)
__________________________________________ (4)
 ______ (11)
______ (11)












 _______ (11)________________________ (12)
_______ (11)________________________ (12)
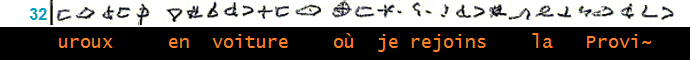 ___________________________________________________________________________ (13)
___________________________________________________________________________ (13)




 ________________________ (14)
________________________ (14)

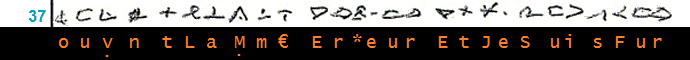






 ___________________________________________________________ (15)
___________________________________________________________ (15)
 ________(4)
________(4)
 ________________ (16)
________________ (16)
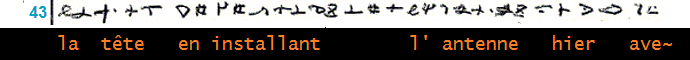








~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Notes ~~~~~~~~~~~~~~~~~~~~~~~~~~~~
j'accompagne Guil~
NB- L'État et le prénom s'écrivent habituellement Tennessee ; mais on trouve parfois Tennessie pour le prénom.
- les troupes scoutes sont couramment désignées par leur numéro ordinal et la ville (par exemple la 90ème Paris ) ;
- dans un tableau résumant ses activités, une troupe de Gien cite par deux fois le nom de la 1ère Meung-sur-Loire .
[In]certitudes
La transcription proposée plus haut est évidemment biaisée puisqu'elle a été établie après le décryptage effectué par Tony Gaffney ; si on ne le connaissait pas, on transcrirait probablement  par C (et non u ) ou
par C (et non u ) ou 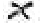 par x (et non C ) ; les lignes de transcription ci-dessus auraient été totalement différentes ; mais cela n'aurait pas changé les statistiques qui suivent : mêmes pourcentages, même calcul de l'entropie. Par contre, les choses auraient pu être un peu différentes quant à la répartition des signes, et cela à deux niveaux :
par x (et non C ) ; les lignes de transcription ci-dessus auraient été totalement différentes ; mais cela n'aurait pas changé les statistiques qui suivent : mêmes pourcentages, même calcul de l'entropie. Par contre, les choses auraient pu être un peu différentes quant à la répartition des signes, et cela à deux niveaux :
 et
et  sont un seul et même signe (variété de e ultérieur ) mais
sont un seul et même signe (variété de e ultérieur ) mais  et sont deux signes différents (respectivement m et a ) ; que choisirait-on sans connaissance préalable du décodage ?
et sont deux signes différents (respectivement m et a ) ; que choisirait-on sans connaissance préalable du décodage ?- sans doute verrait-on dans
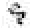 une variété de
une variété de 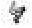 (transcrit p ), alors que le décodage indique qu'il s'agit d'un R .
(transcrit p ), alors que le décodage indique qu'il s'agit d'un R .
On se retrouve un peu dans la situation de qui cherche à jouer aux échecs contre soi-même, et l'exercice peut paraître un peu vain ; mais l'incertitude ne porte que sur une frange des données, et celles-ci n'ont pas d'ambition scientifique démesurée. Voici donc les fréquences des caractères et quelques autres mesures pour
| note sur alphabet complet ≠ réduit (*) __ Nombre de caractères __ Taille de l'alphabet __ Indice de coïncidence __ Entropie __ Coefficient de diversité % Pourcentage Nb Nombre d'occurrences Car Caractère | Ⓐ Transcription 1244 67 0,0339 5,33 46,53 % Nb Car 6,7 83 n6,3 78 a 5,7 71 i 5,5 68 t 5,3 66 u 5,1 64 € 5,0 62 o 4,7 58 r 4,3 53 e 4,1 51 s 2,6 32 A 2,3 28 L 2,2 27 l 2,1 26 D 2,0 25 r 2,0 25 * 1,9 24 P 1,7 21 E 1,7 21 | 1,6 20 m 1,5 19 c 1,4 18 T 1,4 17 M 1,4 17 C 1,4 17 ' 1,3 16 ? 1,1 14 S 1,1 14 J 1,0 12 d 0,9 11 i 0,9 11 b 0,8 10 Q 0,8 10 u 0,8 10 h 0,6 8 x 0,6 8 v 0,6 8 p 0,6 8 l 0,6 8 I 0,6 8 F 0,6 8 h 0,6 7 R 0,5 6 M 0,5 6 G 0,5 6 g 0,5 6 d 0,4 5 V 0,4 5 v 0,4 5 g 0,3 4 U 0,3 4 O 0,2 3 s 0,2 3 N 0,2 3 j 0,2 3 B 0,2 3 1 0,2 2 X 0,2 2 q 0,2 2 S 0,2 2 H 0,2 2 c 0,2 2 - 0,1 1 z 0,1 1 Y 0,1 1 V 0,1 1 L 0,1 1 p 0,1 1 ç 0,1 1 $ 0,1 1 # | Ⓑ Texte décodé (alphabet complet) 1596 54 0,0691 4,23 65,27 % Nb Car 18,1 288 [ ]12,1 192 e 6,3 101 a 5,7 91 r 5,5 88 n 5,4 86 i 5,1 82 t 4,8 77 u 4,7 75 s 4,1 65 l 4,0 64 o 2,6 42 m 2,6 41 d 2,1 34 c 2,1 33 p 1,8 28 é 1,3 20 h 1,2 19 v 1,0 16 ' 0,9 15 j 0,9 14 b 0,8 13 g 0,7 11 q 0,7 11 ; 0,6 10 , 0,5 8 à 0,5 8 x 0,4 7 f 0,4 7 ê 0,3 5 è 0,2 3 1 0,2 3 D 0,2 3 C 0,2 3 T 0,2 3 L 0,2 3 G 0,1 2 â 0,1 2 J 0,1 2 M 0,1 2 î 0,1 2 P 0,1 2 X 0,1 2 - 0,1 1 N 0,1 1 y 0,1 1 F 0,1 1 ù 0,1 1 # 0,1 1 ç 0,1 1 ô 0,1 1 z 0,1 1 A 0,1 1 O 0,1 1 5 Ⓓ L'Assommoir (alphabet réduit) 745406 25 0,0787 3,98 26,8 % Nb Car 17,0 126530 e9,6 71755 a 7,7 57205 s 7,2 54008 i 7,2 53749 t 6,7 50261 n 6,5 48598 l 6,5 48309 r 6,4 47619 u 5,2 38691 o 3,7 27219 d 3,0 22629 c 2,7 19967 m 2,6 19212 p 1,7 12808 v 1,1 8501 g 1,1 8152 b 1,0 7553 f 1,0 7088 h 0,9 6647 q 0,4 3135 j 0,4 2934 x 0,2 1455 y 0,2 1360 z 0,1 21 k 0,0 0 w | Ⓒ Texte décodé . (alphabet réduit) 1274 24 0,0788 4,01 41,88 % Nb Car 18,4 235 e8,8 112 a 7,2 92 r 7,1 90 n 6,9 88 t 6,9 88 i 6,2 79 u 5,9 75 s 5,3 68 l 5,2 66 o 3,5 44 m 3,5 44 d 3,1 39 c 2,7 35 p 1,6 20 h 1,5 19 v 1,3 17 j 1,3 17 g 1,1 14 b 0,9 12 q 0,8 10 x 0,6 8 f 0,1 1 z 0,1 1 y 0,0 0 k 0,0 0 w Ⓓ L'Assommoir (alphabet complet) 954009 94 0,0689 4,46 63,34 % Nb Car 16,6 158203 [ ]11,5 109949 e 7,0 66851 a 6,0 56796 s 5,6 53452 t 5,5 52925 i 5,2 49856 n 5,1 48228 r 4,9 46839 l 4,9 46688 u 3,9 37666 o 2,8 26637 d 2,1 19761 c 2,0 19186 , 2,0 18904 m 1,9 18444 p 1,3 12365 v 1,1 10641 é 0,9 9025 ' 0,8 7893 . 0,8 7514 b 0,8 7437 f 0,8 7423 g 0,7 7008 h 0,7 6357 q 0,6 5742 [ ] 0,4 3391 à 0,3 2927 x 0,3 2855 j 0,3 2436 è 0,2 2283 - 0,2 1921 ! 0,2 1759 L 0,2 1737 ê 0,2 1672 E 0,2 1581 C 0,2 1454 y 0,1 1404 ; 0,1 1349 z 0,1 1133 ç 0,1 1078 G 0,1 1063 M 0,1 990 – 0,1 889 A 0,1 771 I 0,1 768 P 0,1 752 … 0,1 638 B 0,1 627 O 0,1 622 â 0,1 582 D 0,0 452 ? 0,0 447 : 0,0 443 V 0,0 431 û 0,0 409 S 0,0 405 N 0,0 397 ô 0,0 324 ù 0,0 297 T 0,0 297 î 0,0 290 Q 0,0 280 J 0,0 180 _ 0,0 176 U 0,0 154 Ç 0,0 116 F 0,0 89 É 0,0 81 R 0,0 80 H 0,0 39 « 0,0 38 » 0,0 19 k 0,0 16 = 0,0 15 ï 0,0 11 Z 0,0 9 2 0,0 8 1 0,0 7 X 0,0 4 ë 0,0 4 9 0,0 3 3 0,0 2 K 0,0 2 Ê 0,0 2 À 0,0 2 8 0,0 1 Y 0,0 1 Ô 0,0 1 7 0,0 1 5 0,0 1 0 0,0 1 ° 0,0 1 ) 0,0 1 ( |
<!> en plaçant le curseur sur la colonne Ⓑ, on affiche les valeurs de Ⓔ qui correspond à Ⓒ ; inversement, en plaçant le curseur sur Ⓒ , on affiche les valeurs de Ⓓ qui correspond à Ⓑ ; ce comportement un peu étrange permet de comparer les statistiques des deux textes calculées suivant les mêmes principes.
Quelques observations sur ces mesures :
- Taille de l'alphabet : comme on l'a constaté à propos des signes pointés (voir aussi la discussion [⇒] portant sur le carnet ST James ), on peut avoir à se demander si, dans le texte à décrypter, tel signe est autonome ou ne forme qu'une variante d'un autre ; mais ces incertitudes portent sur une part relativement limitée de l'alphabet (de l'ordre de dix pour cent en général).
Paradoxalement, c'est sur la taille de l'alphabet du texte en clair que l'hésitation et les écarts sont les plus forts :
• si on applique au texte décodé le même principe qu'au texte chiffré (en fait, le nombre de caractères Ascii différents utilisés pour la transcription), on arrive à 54, et L'Assommoir en compte 94 ; la liste établie à partir des articles de Wikipédia en français arrive à un total un peu plus bas mais elle ne distingue pas les majuscules des minuscules – ce qui nous mène à 110 tout compris ;
• pourtant, si vous demandez à quelqu'un combien il y a de lettres dans l'alphabet, vous obtiendrez le plus souvent comme réponse vingt-six ; et c'est le même principe que suivent certaines tables de fréquence (par exemple, celle que publie le site nymphomath.ch ) ou les sections de divers sites consacrés au codage de Vigenère.On est donc conduit à distinguer
espaces, chiffres, ponctuation Majuscules/minuscules signes diacritiques exemple Alphabet complet prises en compte comme caractères autonomes 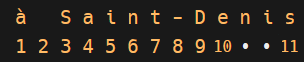
Alphabet réduit supprimés confondues confondus avec
la lettre simple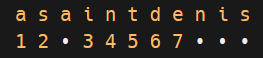
C'est habituellement l'alphabet complet qui est pris en compte ici, mais certaines comparaisons avec l'alphabet réduit peuvent être intéressantes.
retour à Un peu de vocabulaire –c_____c– retour au tableau des statistiques - Fréquence : c'est la mesure la plus parlante ; comme la page consacrée au carnet ST James [⇒] en fait grand usage (sur les traces de Dennis Stallings), nous nous limiterons ici à la comparaison entre le texte crypté et les deux états du texte décodé.
Ce qui frappe au premier abord, c'est l'aplatissement de la courbe dans LdV ; et l'on serait tenté de considérer le phénomène comme banal puisque ce texte utilise plus de signes que la version décodée (67 contre 54) ; mais c'est là que la comparaison avec l'alphabet réduit est utile :
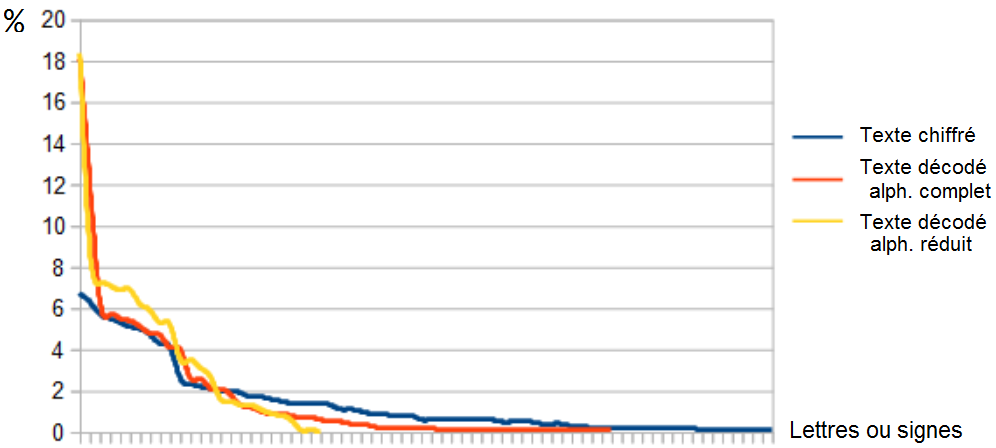
. la courbe pour l'alphabet complet de 54 lettres est plus proche de celle de l'alphabet réduit de 24 lettres que du texte chiffré avec ses 67 signes ; c'est donc que la taille de l'alphabet influe moins que la nature et le fonctionnement de cet alphabet. Et en effet, on peut observer que les particularités du système choisi pour LdV concourent toutes à rétrécir les écarts de fréquence :
Particularités Exemple du l dans LdV Texte décodé • distinction entre signes initiaux
__________________et ultérieurs28 (41,2 %)
27 (39,7 %)Majuscules : 3 ( 4,4 %)
minuscules : 65 (95,6 %)• signes pointés 9 (13,2 %) absents • * (signe de redoublement) 3 ( 4,4 %) absents Enfin, si l'on compare les valeurs de LdV , de L'Assommoir et de la nouvelle de Maupassant Le Horla , on peut observer deux différences plus anecdotiques mais intéressantes :
Lettre Fréquence Commentaire G
majusculeLdV 0,239 %
L'Assommoir 0,145 %
Le Horla 0,004 %Cette lettre est nettement plus présente dans LdV et même L'Assommoir que dans Le Horla ; c'est certainement dû à la présence de Guillaume dans le premier texte, de Gervaise et Goujet dans le second. s
alph. réduitLdV 5,9 %
L'Assommoir 7,7 %
Le Horla 8,3 %La différence est moins nette, mais le s (majuscules et minuscules confondues) est clairement moins fréquent dans LdV que dans les deux autres textes – et cette fois, je n'ai pas trouvé d'explication. - Indice de coïncidence : en simplifiant, on peut considérer que cet indice condense en une seule valeur les différentes fréquences des lettres, et est alors caractéristique de chaque langue ; le site dcode.fr donne ce tableau :
Français
Espagnol
Allemand
Italien
Russe
Anglais0.0778
0.0770
0.0762
0.0738
0.0667
0.0529certains écarts sont faibles (l'espagnol est à 1 % du français et de l'allemand), et parfois ambigus (un autre site donne 0,74 pour le français et 0,72 pour l'allemand, plaçant ces deux langues en dessous de l'italien) mais l'utilisation principale de cet indice est de déterminer si un texte chiffré l'est par simple substitution (avec une mesure proche de la valeur de référence de la langue) ou non : par substitution homophonique (comme LdV avec 0,35) ou par code de Vigenère, où cet indice permet en plus de retrouver la longueur de la clé.
NB- Qu'il s'agisse des fréquences ou de l'indice de coïncidence, ces deux mesures sont insensibles à la longueur du texte et à l'ordre dans lequel les caractères apparaissent dans le texte. - Entropie : pour plus de précisions sur la réalité scientifique de l'entropie appliquée à un texte (entropie de Shannon), on peut se reporter à cette page [⇒] du site dcode.fr (qui offre aussi un calculateur) ou à la page de Wikipédia ; on peut constater que son utilité première est d'indiquer le nombre de bits nécessaires pour encoder un texte donné sans perte d'information – domaine plutôt pointu ; mais il se trouve que, comme les deux précédentes, cette valeur varie (plus ou moins) d'une langue à l'autre, notamment en fonction de la taille de l'alphabet ; d'où une extension de ses emplois.
Pour les textes qui nous occupent, la valeur tourne autour de 4 pour les mesures en alphabet réduit et, pour l'alphabet complet, de 4,2 (LdV décodé - avec une ponctuation très limitée) à 4,46 (L'assommoir , employant une typographie plus variée), s'opposant aux 5,33 de la transcription.
NB1- les mesures peuvent aller de 0 (voir plus bas le « texte » n° 2) à 8 puisque chaque caractère est codé sur un octet composé de 8 bits ;
NB2- le programme ent.exe de John Walker (que l'on peut trouver sur cette page [⇒] de son site) permet d'obtenir l'entropie d'un texte (et quelques autres mesures non reprises ici). - Coefficient de diversité : les trois mesures précédentes ont en commun de ne pas varier si l'ordre des caractères du texte est modifié ; par exemple, les anagrammes aaaaaabbbbbbcccccc et aaabacbabbbccacbcc ont le même niveau d'entropie (1,585) et le même indice de coïncidence (0,2941) ; il paraissait donc intéressant d'ajouter une mesure tenant compte de cet ordre ; qu'une telle mesure existe déjà, c'est vraisemblable mais je ne l'ai pas trouvée ; d'où ce coefficient de diversité :
étapes du calcul de l'indice exemples d'application à LdV • pour chaque lettre de l'alphabet du texte
___• lister les lettres contiguës
_______(venant juste après la lettre considérée) ;
___• compter le nombre d'occurrences de chaque lettre contiguë ;
___• transformer ce nombre en pourcentage ;
___• retenir le pourcentage le plus élevéaprès g après q
espace a e é o r u
1 2 4 2 2 2 11
8 15 31 15 15 15 100
31 % 100 %• pour l'ensemble des lettres de l'alphabet du texte,
___• faire la moyenne des pourcentages les plus élevés
___• ôter cette valeur de 100
65,27
34,73On aura alors 11,313 pour aaaaaabbbbbbcccccc et 64,667 pour aaabacbabbbccacbcc ; d'une façon générale, plus la palette de possibilités est étendue et plus l'indice est élevé, avec un minimum de 0 quand chaque lettre ne peut être suivie que d'une seule et même lettre (cf. textes n° 1 et 2 plus bas) et un maximum de 100 - (100 divisé par la taille de l'alphabet) quand chaque lettre peut être suivie de n'importe quelle lettre de cet alphabet (soit approximativement entre 95 pour un alphabet réduit et 99 pour un alphabet complet).
NB- on pourrait envisager de calculer cet indice autrement :
• de façon plus simple en faisant la moyenne du nombre de lettres contiguës possibles ;
• de façon plus élaborée en reprenant le pourcentage maximal mais en le pondérant par la fréquence de la lettre. - Quelques tests : à titre informatif, voici les résultats pour quelques exemples ; les premiers sont très artificiels mais aident à fixer les idées ; les derniers reprennent les textes précédents en essayant de faciliter les comparaisons :
Texte Indice de
coïncidenceEntropie Coefficient
de diversitéNotes 1 caractères Ascii (1) 0 (2) 7,5774 100 (1) Suite de cent quatre-vingt-dix caractères où chacun n'apparaît qu'une fois.
(2)dcode donne 0,066, mais c'est sans doute dû à un traitement différent de certaines lettres comme œ .
(3)planetcalc indique 0,065 – mais là encore, c'est lié vraisemblablement à l'emploi de lettres à diacritiques pour transcrire (en interne) les signes pointés.
(4) Cette valeur élevée vient sans doute de l'absence de séparation des mots, comme dans deuxheuresdu ; même tendance dans LdV mais moins marquée en raison de la brièveté de l'extrait.2 aaaaaaaaaaaaaaaaaa 1 0 0 3 abcabcabcabcabcabc 0,29412 1,585 0 4 aaabacbabbbccacbcc 0,29412 1,585 64,667 5 aaaaaabbbbbbcccccc 0,29412 1,585 11,313 6 LdV - transcription 0,068 (3) 5,2638 53,116 7 LdV décodé - alph. complet 0.0709 4,4228 36,056 8 LdV décodé - alph. réduit 0,0788 4,0049 58,125 9 L'Assommoir - alph. complet 0,0689 4,4581 36,656 10 L'Assommoir - alph. réduit 0,0787 3,9815 73,2 (4)
Livre et carnet
Il est difficile, quand on consacre un peu de son temps à ce Livre de vie , de ne pas penser au carnet ST James ; cette confrontation (où renaît le malaise évoqué au début de cette section) fera l'objet d'une annexe dans la section consacrée à James Hampton.
Plan du site & Mentions légales_._Site éclos sur Skyrock, développé avec Axiatel et mûri sur Strato.com_._© 2015-2026 - XylonAkau